该方案分为标准版和高阶版两个版本。前者在单颗武当C1200家族中算力平台上即可部署,而后则可在即将推出的华山A2000家族中发挥全部实力。
官方表示,黑芝麻智能的端到端智驾系统,一步到位采用了One Model的架构。一端可输入摄像头、激光雷达、4D毫米波雷达、导航地图等信息,另一端直接输出驾驶决策所需要的信息,即本车的预期轨迹。
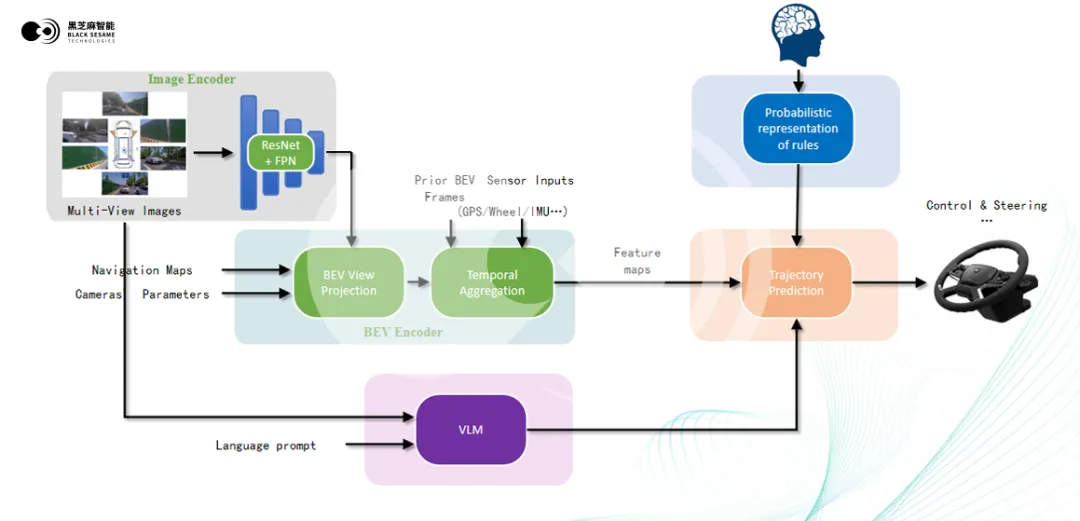
具体到模型内部,其可以分为BEV编码器和决策(轨迹预测)两个神经网络单元。
BEV编码的工作过程中,车外摄像头或激光雷达、4D 毫米波雷达等各类传感器的数据进入 ResNet 和 FPN 等主干网络,提取并融合多层特征,生成多尺度特征金字塔。经过几何变换,特征图对齐成俯视视角(BEV),实现统一的空间表示。
随后,系统通过多尺度时序聚合将当前与历史 BEV特征融合,减少噪声干扰,增强动态物体感知精度和系统鲁棒性,最终生成特征图(Feature Maps)传递至决策单元,用于生成车辆的预期行驶轨迹。
BEV和决策两个神经网络单元之间传递的是特征图(Feature Maps)。由于这些基础特征图没有人为定义的接口和处理过程,所以信息可以更为原始和完整地传递,以便于网络进行优化和决策。
与此同时,用Feature Maps将两个单元进行连接,还可以以back-propagation反向传播的方式——即通过计算最终输出的轨迹与实际目标之间的误差,然后将该误差反向传播到决策和BEV单元——来进行两个神经网络单元的联合训练和参数调优。
黑芝麻智能表示,One Model架构既解决了多模块之间可能存在的信息传递损耗问题,又实现了感知和决策单元的联合训练,实际效果会更佳优秀。
黑芝麻智能团队还更进一步,通过引入VLM(视觉语言大模型)和规则的概率化表征(Probabilistic Representation of Rules,以下简称 PRR)两个模块,来进一步提升端到端系统决策的准确性和灵活性。
VLM 模型基于开源 VLM 模型改进而来,该模型可同时接收图像和语言输入信息(比如用户的导航指令),然后通过 Transformer 结构中的交叉注意力机制将视觉和语言两种模态的信息相互关联,从而让模型更深层地理解当前的场景,并以符号特征的形式,将对于场景的理解输入到决策单元中。
例如,当系统识别到行人在斑马线上移动的视觉信息,VLM 可以通过语言规则的匹配,理解这个场景是“行人在过马路”,并且知道此时应该停车或者减速——将这种信息传递给轨迹预测模块,显然能够帮助其做出更加正确的驾驶决策。
除了有 VLM 子模块的帮助,决策单元还有行车规则的概率化表征模块(PRR)提供信息。
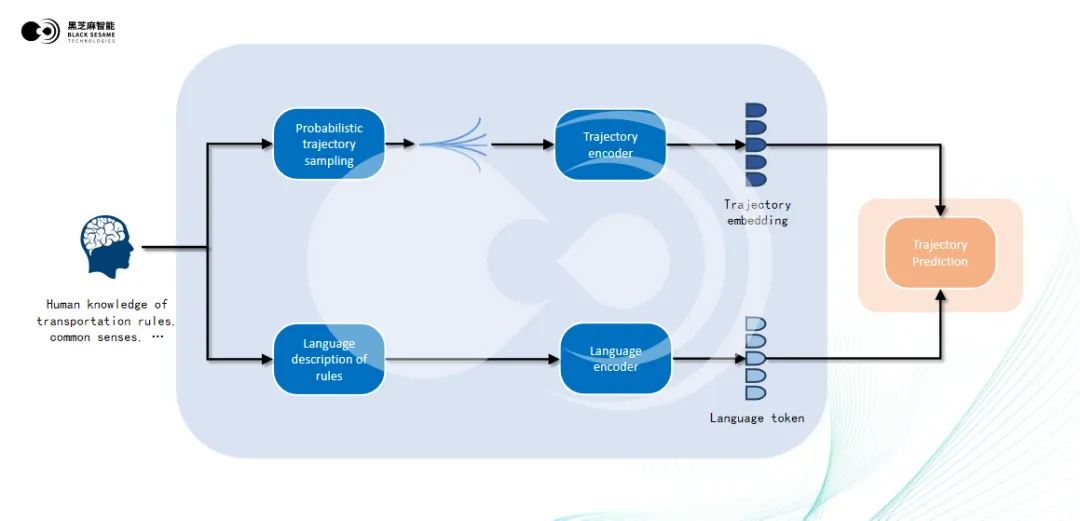
该模块用于将人类的驾驶常识和交通规则转化为自动驾驶系统可理解的概率分布,再通过概率化轨迹采样生成符合交通规则的候选轨迹,并为每个选项赋予相应的概率权重。例如,在交叉路口,系统可以生成“等待”“缓慢通过”等符合规则的选项,并赋予相应的优先级。
此外,该模块还包含规则的语言描述部分,将交通规则和驾驶指令编码为语义特征,使其能够被决策模块理解和应用。例如,红灯停车或右转让行的规则会生成特定语义向量。
PRR输出的两种信息均会进入到决策单元,与BEV单元输出的特征图、VLM输出的场景理解特征互相融合,最终生成一条最佳的目标行驶轨迹。
最后官方补充一点,VLM和PRR模块本质上是端到端系统的增强型“外挂”,它们额外引入了类人的对于场景的综合理解能力,以及常识和交规的语义表征,从而在扩展轨迹决策能力的同时维持了端到端系统的整体工作原理, 其本质上相当于一个功能增强了的One Model架构。


